Apache Cassandra:学习笔记
1. 总览
1.1 Cassandra 是什么
- 分布式 NoSQL 数据库
- 数据模型: column-family partitioned row store,支持结构化数据
- 一致性: 最终一致性,Dynamo 风格复制模型
- 高可用: 无单点故障(AP)
- 可伸缩: 支持扩展机器提升性能
1.2 设计目标
- 多主复制
- 全局高可用,低延迟
- 现代硬件上具有可拓展性
- 吞吐量随集群处理器数线性拓展
- 在线自动均衡
- 集群在线扩容
- 分区的,面向键的查询
- 灵活的 Schema
1.3 名词解释
Keyspace
相当于数据库中的 database。一个 Keyspace 是数据物理隔离的单位,可以定义数据副本,复制方式等内容。一个 Keyspace 可以有多个 Tables。
Table
相当于数据库中的 table,所有行具有相同的 Schema,支持在线添加列。一个表可能分布在多个物理节点上。
Partition
一个 Table 中的数据,物理上会按照 Hash Range 分区,切分为多个 Partition,一个 Partition 的数据存储在虚拟节点上。数据存储在哪个分区由它的分区键决定,每一行数据行必须有一个主键,分区键由主键决定。
Row & Column
一行数据由一个主键和其他 Field 构成。每列数据必须有相同的类型。其中有几个重要的概念:
- Partition Key: 用于数据分区分片的 Key
- Clustering Key: 决定同一个分区内,相同 Partition Key 的排序
- Primary Key: 通常由 Partition Key + None or Many Clustering Keys 组成
CQL
一种类似 SQL 的语言,用于对数据进行查询操作,以及对 Schema 进行定义和修改。它支持
- 基于 CAS 的 单分区清理级事务
- 用户定义的类型,函数和聚合函数
- 集合类型:Set,Map,List
- 本地二级索引
- 物化视图
但同时,Cassandra 不支持跨分区的事务,比如
- 多分区事务
- 分布式连接
- 外键和参照完整性
2. Dynamo
Apache Cassandra 参考了 Dynamo 的设计范式。在 Dynamo 中,每个节点维护三个主要组件
- 数据管理: 对分区进行协调的组件
- 集群管理: 基于哈希环的成员管理,故障检测
- 存储: 一个本地持久化的 key-value 存储
Cassandra 主要借鉴了前两个组件,存储是用基于 LSM 的存储引擎,并有着 Dynamo 风格的集群管理
- 使用一致性哈希进行数据分区
- 使用多主复制,数据带版本号
- 使用 gossip 协议进行集群管理
- 能在现代硬件上拓展
Cassandra 希望做到
- 管理 PiB+ 级别数据,并进行复制
- 保证低延迟读写
2.1 数据分区
Cassandra 使用 Range Hash Partition。每个分区被复制到多个节点,通常跨机架甚至跨 AZ。
解决数据冲突
Dynamo 使用版本号 + 向量时钟协调多主冲突。 Cassandra 使用版本号 + Last-Write-Wins Element-Set CRDT 协调多主冲突。
一致性哈希
Cassandra 将一个节点映射为散列环上的一个或多个令牌。 假设复制因子为 RF,数据 key 顺时针向前走,遇到的第 [1, RF) 个节点就是它应该存储的节点。
虚拟节点(vnodes)
Dynamo 使用虚拟节点解决分片不均衡的问题。Cassandra 也是这样做的,它引入了一些术语:
- Token: 在 hash ring 上的一个点
- Endpoint: 就是 IP + 端口
- Host ID: 一个物理节点的唯一标识符
- Virtual Node(vnode): hash ring 上的一个 token
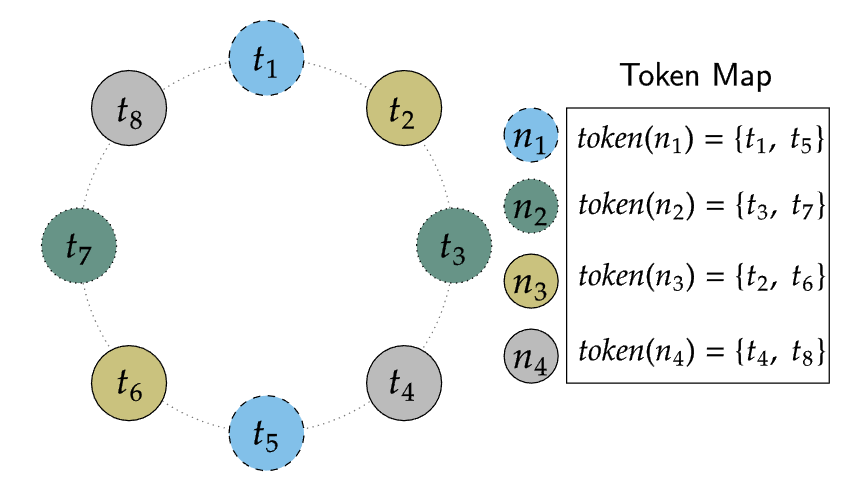
Token Map 是 Tokens 到 Endpoints 的映射,Cassandra 通过这个表来追踪哈希环上的一个 token 属于哪个物理节点。Cassandra 有多种生成 vnode token 的方法。
- 随机令牌分配器: 为了保持数据均衡,每个节点的虚拟节点数会很大,达到256
- 确定性令牌分配器: 智能地挑选令牌,使得数据均衡的同时,虚拟节点数会比较少
2.2 数据复制
复制策略
每个 Keyspace 都可以自定义复制策略,有下面几种:
- NetworkTopologyStrategy
- 可以对每个数据中心指定数据的复制因子(Replication Factor,RF)
- 可以指定不同机架作为副本选择
- 可以指定一个机架可以容纳的副本数
- 缺点:机架感知要求每个机架上的节点数量必须为偶数,不然可能导致数据非常不均衡
- SimpleStrategy
- 所有节点都是平等的,没有数据中心,机架的概念
- 不能在实际生产中使用
版本号
Cassandra 使用时间戳版本号,用于保证最终一致性。
- 所有来自客户端的修改请求,都带有一个来自客户端时钟的时间戳
- 如果发生冲突,最后写入操作获胜
- Cassandra 的正确性取决于时钟的正确性
对于集合类型,Cassandra 使用了 LWW-element Set CRDT 解决。
副本一致性
为了保证副本间的最终一致性,Cassandra 使用了反熵过程(anti-entropy process)和尽力而为(best-effort)的修复策略进行副本间数据的同步。
反熵过程
反熵过程是指: 定期查找副本之间数据差异,将任何缺少的数据从一个副本复制到另一个副本,从而达到副本间最终一致。和 Dynamo 一样,Cassandra 使用了 Merkle 加速反熵过程。
- 为每个副本的 KeySpace 创建 Merkel 树
- 叶子节点对应 Memtable 或 SSTable
- 父节点的值是两个子节点值的哈希
- 副本间可以自上而下比较 Merkle 树来识别不匹配的数据
- 最终定位到叶子节点,不匹配的数据根据一定的修复策略进行修复
Cassandra 对反熵修复的创新。
- 子范围修复: 其实就是对 Hash Range 中的一小部分建 Merkle 树
- 增量修复: 只修复自上次修复以来发生变化的分区
Best-effort 修复策略
- 读修复 Read Repair: 每 N 个读操作触发一次修复动作
- Hinted Handoff: 节点宕机后,该节点负责的数据写到别的节点上,节点恢复后再写回来
- 手动 Repair: 支持全量和增量 Repair
NWR 协议
Cassandra 和 Dynamo 一样,使用 NWR 协议进行写入和读取,其中要求 R + W > N。其中 R 和 W 的值可以根据业务需求进行调整。
2.3 集群管理
Gossip
Gossip 是 Cassandra 用于维护最终一致的集群元数据的一致性协议。它由三个部分组成:
- 直接邮寄: 状态变化后,随机选择一些节点,发送新的数据
- 反熵: 集群中的节点,定期随机选择其他节点,相互交换数据消除两者间差异
- 谣言传播: 一个节点受到新消息后,它就变成活跃状态,随机选择其他节点发送新数据
Cassandra 对在每个发出的 Gossip Message 中都附加了 (generation, version) 字段。generation 是一个单调的时间戳,代表这些信息的版本号。version 是一个 Lamport 逻辑时钟。
除此之外, Gossip 还会传播 token 的元数据和 Schema 版本号,这些信息构成了调度数据移动和模式拉取的控制平面,并告诉每个节点,哪个节点拥有哪些数据。 Cassandra 集群中的每个节点都周期性的互相八卦,八卦的周期为每秒一次,每次八卦都会
- 更新 version,并构建一个在当前节点视角的一个视图
- 在集群中随机挑选一个节点跟它八卦
- 概率性地试着
- 和主观离线的节点八卦
- 如果八卦失败,跟种子节点闲聊,并告诉种子节点这个情况
上面提到了种子节点,它相当于一个群的群主,而且可以有多个。种子节点和非种子节点的唯一区别是:种子节点可以拉人进群聊(引导节点加入哈希环),而非种子节点不能。一般来说,一个机架或者数据中心应该有至少一个种子节点,这样可以减少跨机架网络流量,并提高集群管理的性能。
成员管理与故障恢复
Gossip 是 Cassandra 进行成员管理的一致性基础。故障检测器(failure detector)最终决定节点是否可用。Cassandra 和 Akka 使用 The Phi Accrual Failure Detector 的思想来判断节点故障与否,它的思想在于:
- 故障检测器是不可靠的: 原因是无法区分 Crash 和 Slow
- 基于心跳的故障检测: 如果心跳超时,给一个 Crash 的概率
- 自适应故障检测: 网络情况不断变化,因此心跳超时 Crash 的概率也不同
- 根据 Crash 的概率,到达给定的阈值,认为节点宕机
故障检测器虽然可以判断节点是否可用,Cassandra 永远不会将节点从 Gossip 列表中删除,以允许节点的短暂 Failure,除非管理员指定这个节点将被移除。
3. 存储引擎
感觉就是一个 RocksDB。写 Memtable 前先写 WAL(CommitLog),Memtable 满了就会 Frozen,异步刷盘到 L0 层 变成 SST 文件。然后 SST 文件之间可能触发合并,引起 Compaction。 和 RocksDB 不一样,Cassandra 也有一些特点
- wide-column storage model: Cassandra 是 column-family partitioned row store(行存)
- 一个 KeySpace 一个 LSM: 每个数据库属于不同的LSM,数据物理隔离
- LSM Compactor: 按照
table_name, hash(partiton_key), clustering_keys排序
4. 一致性与事务保证
- 正常的读写就是 AP,满足最终一致
- 支持轻量级的单分区事务,是用 Paxos 实现的
- 二级索引只能保证和本地副本一致