Percolator:Large-scale Incremental Processing Using Distributed Transactions and Notifications 论文阅读
1. 摘要
1.1 背景
- 从前 MapReduce 跑网页索引 需要跑全量互联网的页面,并存储在 BigTable 中。
- 随着页面数量越来越多,开销和耗时越来越大。
- MapReduce 只能全量更新,不能增量更新。
- 为了只处理增量的新页面,Google 将索引的维护抽象成事务,通过执行一系列的并发事务来解决。
1.2 概述
- Percolator 在 BigTable 单行事务基础上,实现了多行事务,
- 通过 MVCC 和一个全局授时服务器(Timestamp Oracle,TSO)来实现快照隔离(Snapshot Isolation,SI)语义的分布式事务能力。
- 本文将着重讲解 Percolator 和它的前身 2PC 协议,对原论文的 Observer 机制会略过。
2. 两阶段提交 Two Phase Commit
2.1 两个角色
- 一个 Coordinator 协调者:负载事务的协调,以库或者单独服务的形式出现。
- 多个 Participant 参与者:负载具体事务的执行,持有具体数据。
2.2 两个阶段
- Prepare 阶段:协调者 向各 参与者 节点发送 Prepare 消息,各 参与者 告诉协调者该事务提交与否。
- Commit 阶段:协调者 收到各 参与者 的所有响应。任一节点不同意提交,事务回滚。否则提交事务。
2.3 存疑状态
对于参与者来说,当它在 Prepare 阶段回复YES时,就进入了 存疑(uncertain)状态,直到收到 协调者 发来的 Commit 请求。在存疑状态时,整个事务可能已经提交,也可能没有提交。
对于客户端来说,它与协调者进行交流。当协调者意外退出时,客户端进入了存疑状态,对事务提交与否不知情。
显然协调者对于事务执行情况是最清楚的,在协调者眼中,一个事务被提交与否,取决于当前是否越过提交点。
2.4 提交点 Commit Point
2.4.1 单机事务的提交点
单机事务实现原子性并不复杂,一般的做法是:将事务提交前的写入存放在预写日志中,事务提交时,往磁盘追加一条提交记录,完成事务提交。
所谓提交点(Commit Point),就是指提交记录刷盘那一刻。在此刻之前,事务的所有写入都是未提交状态,可以被回滚或中止。而在提交点之后,整个事务提交成功。
2.4.2 提交点的本质
提交点将多个操作的提交规约到单点提交问题,确保了事务的原子性。在 2PC 中,由于一个事务会牵扯多个节点,要保证事务原子性,必须满足提交点原子性。有以下几种方案:
2.4.3 协调者写入 提交记录 时为 提交点
思想:协调者在发起提交阶段之前,在本地记录一份提交记录,提交记录被持久化标识着事务提交成功。
细节:需要在事务开始前,对事务的参与者列表进行持久化。
故障恢复:
- 在提交点前崩溃了,由于没有提交,只需告知参与者列表中所有参与者,事务中止(abort)。
- 在提交点后崩溃了,告知参与者列表中所有参与者,事务完成。
X/Open XA 事务就是采用这种方式,它依赖于可靠的协调者,需要保证协调者崩溃后能恢复服务且不丢失数据。
2.4.4 所有参与者完成第一阶段时 为 提交点
思想:在协调者写入提交记录时为提交点方案中,提交记录被持久化仅当所有参与者回复YES。因此提交点可以前移到所有参与者回复YES,从而避免刷盘的延迟。
细节:
- 参与者列表在协调者维护:需要在事务开始前,对事务的参与者列表进行持久化。
- 参与者列表在参与者维护:在 Prepare 阶段时,将事务的参与者列表发给参与者。
故障恢复:
- 先获取事务参与者信息。
- 询问事务的所有参与者,Prepare 阶段的响应情况
- 如果所有参与者回复的不是
YES,那么回滚事务 - 否则提交事务
Oceanbase 据说采用这个方案。优点是避免了刷盘的延时,但是协调者崩溃后恢复成本较高。
2.4.5 某一特殊的 参与者 完成 Commit 阶段 为 提交点
思想:从参与者中选一个作为 Primary,以 Primary 提交成功作为事务的提交点。(Percolator 思想)
细节和故障恢复:协调者不持久化任何事务状态,由参与者进行故障恢复,具体见下一章的 Percolator 讲解。
TiDB 采用该方式,优点是不需要考虑 协调者 可靠性(为什么会在本文 Percolator 讲解章节指出),缺点是延时是三者中最高的。
3. Percolator
3.1 总体设计
- 提交过程中的第一个参与者,被设计为类似两阶段提交协调者的角色,整个事务的原子性以它为准。
- 借用 Bigtable 的高可用存储,免去设计协调者的风险和麻烦。
- 通过 Bigtable 的时间戳维度实现数据多版本。
- 采用 TSO 全局授时机制,通过全局时间戳实现多版本管理,从而实现了 SI。
3.2 TSO
相当于一个授时中心,需要保证任何申请的时钟不重,并严格递增。但是需要高并发和高可用。
3.2.1 优化
- 定期分配一个范围的时间戳,并持久化其最大值$T_{max}$。
- 在内存中原子递增快速获取时间戳。
- TSO 崩溃恢复后,分配一个范围比$T_{max}$更大的时间戳
- Worker 批量获取时间戳
- 通过 Paxos/Raft 保证存储高可用即可
3.2.2 其他的一些时序方案(转)
- 逻辑时钟:DynanoDB
- True Time API:Spanner
- 混合逻辑时钟:CockroachDB
3.3 数据存储
3.3.1 Bigtable
Percolator 数据存储在 Bigtable 中,它支持单行事务,查询格式如下:(row, col, timestamp) -> value
Percolator 定义了 4 个列,分别为 Key,Data,Lock,Write。Key 指数据的键,一个 Key 可以有多行数据,每一行的时间戳都不相同。
在每一行中,分别有 Data,Lock,Write 三个字段。假设 start_ts为事务开始时间,commit_ts为事务提交时间。
3.3.2 Data
存储数据的列:(key, start_ts) -> value
3.3.3 Lock
事务的锁:(key, start_ts) -> lock
其中lock的类型有两种,一种是primary,一种是secondary。
如果lock指向自己,那么就是primary锁,否则就是secondary锁。
3.3.4 Write
已提交数据对应的时间戳:(key, commit_ts) -> start_ts
一个键读取时,会找到最近的已提交的时间戳start_ts,通过(key, start_ts)读取value来确保 SI。
3.3.5 一些思考
- Percolator 实际上用
lock字段作为并发控制,data字段作为预写日志,write字段作为提交标志。 - 通过 TSO、Bigtable 时间戳和
lock实现了 SI 隔离语义。 - 通过
primary的write字段的持久化作为分布式事务的提交点。
3.4 事务流程
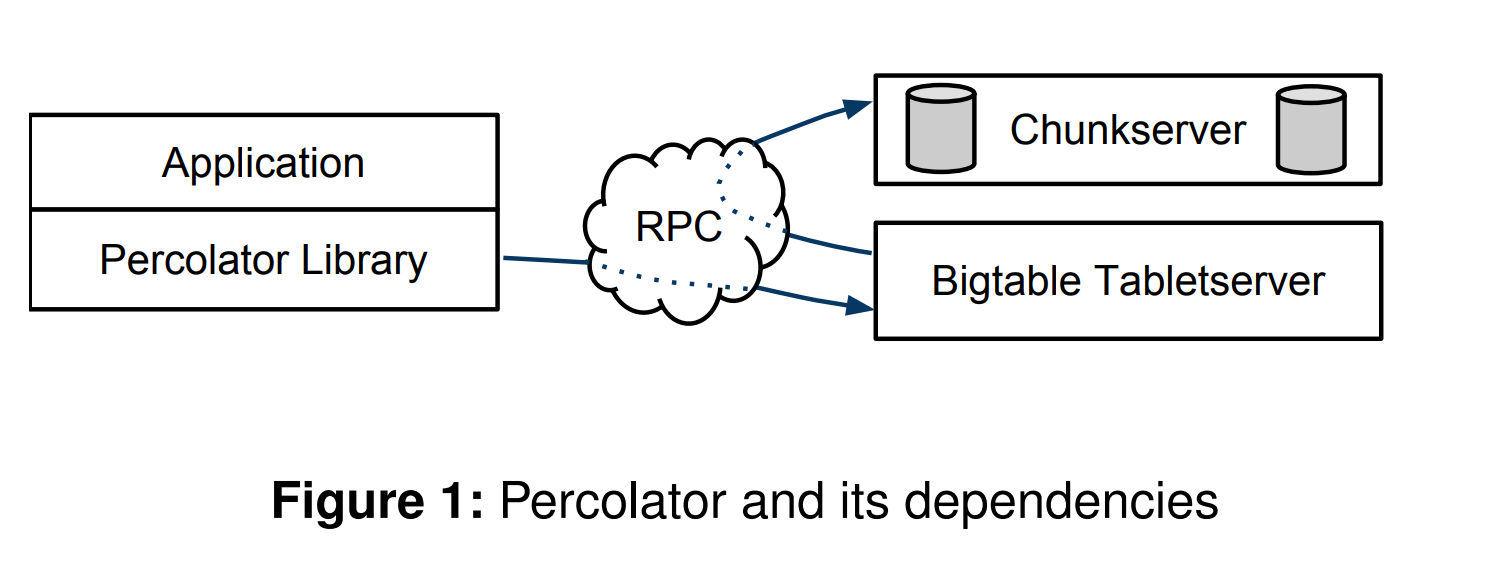
- Percolator 作为一个中间人,它被包装在 Bigtable Client 的上层,应用程序的下层。
- Percolator 是无状态的,作为协调者,它不持久化任何状态信息。
- 当应用程序发起写事务时,Percolator 会先向 TSO 获取一个事务开始时间
start_ts,并使用这个时间戳以 SI 语义读取数据,写入操作将缓存在 Percolator 内部。 - 当应用程序需要提交事务时,Percolator 才真正开始向 Bigtable 写入数据,具体如下:
- Percolator 将第一个写入操作的行作为
primary,充当类似协调者的角色。其他行作为secondary。 Prewrite阶段:该阶段的主要目的是并发检查和预写日志。- 首先,Percolator 会检查
[start_ts, inf)时间戳的write字段,确保该行没有其他事务已经提交。如果已经提交,那么返回失败,事务中止。 - 然后,Percolator 会检查
[0, inf)时间戳的lock字段,确保该行没有其他事务正在运行,如果有,那么返回失败,事务中止。 - 最后,Percolator 通过一个单行事务同时设置
start_ts处的data和lock字段,预写日志并对数据上锁。对于primary,lock字段指向自己,对于secondary,lock字段指向primary。
- 首先,Percolator 会检查
- Percolator 会对
primary和其他secondary行执行Prewrite阶段,任意一次Prewrite失败,事务中止。 - 如果上述流程没有问题,Percolator 会向 TSO 获取一个时间戳
commit_ts表示事务提交的时间,紧接着开始事务的Commit阶段,具体如下所述。 Commit阶段:该阶段会进行事务安全性的检查,如果没有问题,就修改write和lock字段,提交数据- 首先,Percolator 会检查
primary行,在start_ts处上锁的情况。如果没有上锁,意味着别的事务认为当前事务失败了,把锁清理掉了,那么返回失败。 - 如果
primary锁还在,那么 Percolator 可以安全地提交primary行的数据了。这是通过修改write字段为start_ts,并清空lock字段实现的。 - 如果
primary行能安全提交,那么其他secordary行的提交也是安全的,因此 Percolator 将secondary行的write字段修改为start_ts,并清空lock字段。
- 首先,Percolator 会检查
- 提交点:Percolator 的提交点是在
Commit阶段,primary单行事务完成的瞬间。当primary单行事务完成,可以认为事务已经提交了。
上面是 Percolator 执行事务的流程,我们回顾一下上面的要点。下一节将详细介绍每个部分 Percolator 的细节。
- Percolator 被设计为一个无状态的中间层。
- 它利用 Bigtable 时间戳和 TSO 实现 SI。
- Percolator 会选中一行作为
primary,事务的提交与否都使用这行决定。 - Percolator 事务存在两阶段,其提交点是
primary单行事务完成的瞬间。
3.5 Percolator 快照读
3.5.1 大体机制
write行决定了事务的提交状态,只需对于某个时间戳start_ts,只需要通过write列找到最近一次已提交的时间戳T < start_ts,然后读data列(key, T) -> value即可。
3.5.2 崩溃恢复
但是上面的机制不能保证 Percolator 在提交阶段崩溃后,当前事务仍然能找到已提交的数据。我们需要考虑崩溃恢复的情况。如果该行的[0, start_ts]时间段:
- 有一个
lock字段执行自己,那么可能另外的事务正在运行,需要等待锁释放,或已经崩溃。原论文通过一个ack字段,表示事务执行的wall time。如果墙上时间太老,认为这个事务已经崩溃了。如果事务崩溃了,当前运行的事务可以清理掉lock标记位。 - 有
lock字段,但是指向primary lock,同时primary的lock指向自己。同上一种情况。 - 有
lock字段,但是指向primary lock,同时primary的lock不存在。说明上一个事务已经过了提交点,但是secondary单行事务还没有提交。那么我们可以帮助它提交。 - 没有
lock字段,那么可以安全的使用上面提到的机制进行快照读。
class Transaction {
struct Write { Row row; Column col; string value; };
vector<Write> writers_;
int start_ts_;
Transaction(): start_ts_(oracle.GetTimestamp()) {}
void Set(Write w) { writers_.push_back(w); }
bool Get(Row row, Column c, string* value) {
while (true) {
bigtable::Txn T = bigtable::StartRowTransaction(row);
// Check for locks that signal concurrent writes.
if (T.Read(row, c+"lock", [0, start_ts_])) {
// There is a pending lock; try to clean it and wait
BackoffAndMaybeCleanupLock(row, c);
continue;
}
// Find the latest write below our start timestamp.
latest write = T.Read(row, c+"write", [0, start_ts_]);
if (!latest write.found()) return false; // no data
int data_ts = latest_write.start_timestamp();
*value = T.Read(row, c+"data", [data_ts_, data_ts_]);
return true;
}
}
};
3.6 Percolator 特色的两阶段提交
3.6.1 前提概要
- Percolator 在事务正式开始前,会选取第一个写入行作为
primary,其他行作为secondary。 primary字段是整个事务控制的中轴。事务是否提交,关键是primary上的write字段是否持久化。secondary的lock字段通过指向primary,可以快速获知primary的write列状态,从而判断secondary对应的事务是否提交。
3.6.2 Prewrite 阶段
Prewrite 阶段下,Percolator 会对primary和secondary发起Prewrite。可看作2PC的Prepare请求。
- 事务完整性检查:对于每一行,Percolator 会检查
[start_ts_, inf)时间戳是否有已提交的事务,如果有,那么当前事务中止(相当于给协调者回复 NO)。 - 并发检查:对于每一行,Percolator 会检查
[0, inf)是否对该行持有锁,如果有,那么当前事务中止(相当于给协调者回复 NO)。 - 预写日志,占有资源:将写入操作写入
data字段,并在lock字段加锁。
// Prewrite tries to lock cell w, returning false in case of conflict.
bool Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes after our start timestamp . . .
if (T.Read(w.row, c+"write", [start_ts_ , ∞])) return false;
// . . . or locks at any timestamp.
if (T.Read(w.row, c+"lock", [0, ∞])) return false;
T.Write(w.row, c+"data", start_ts_ , w.value);
T.Write(w.row, c+"lock", start_ts_ , {primary.row, primary.col}); // The primary’s location.
return T.Commit();
}
3.6.3 Commit 阶段
Commit 阶段下,Percolator 会先拿到一个提交时间戳,随后进行提交操作。
- 并发检查:先检查
lock字段是否还在。因为在快照读时,可能别的事务误以为该事务崩溃了,清理了该事务占有的资源。如果是的话,那么提交失败。 - 真正提交,释放资源:将
primary的write设置为start_ts,表示start_ts时间戳对应的data已提交,并删除对应的lock。 - 提交
**secondary**:设置secondary的write为start_ts,并删除lock。
bool Commit() {
...
int commit_ts = oracle_.GetTimestamp();
// Commit primary first.
Write p = primary;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
if (!T.Read(p.row, p.col+"lock", [start_ts_, start_ts_]))
return false; // aborted while working
T.Write(p.row, p.col+"write", commit_ts,start_ts_); // Pointer to data written at start ts .
T.Erase(p.row, p.col+"lock", commit_ts);
if (!T.Commit()) return false; // commit point
// Second phase: write out write records for secondary cells.
for (Write w : secondaries) {
bigtable::Write(w.row, w.col+"write", commit_ts, start_ts_);
bigtable::Erase(w.row, w.col+"lock", commit_ts);
}
return true;
}
3.6.4 一些思考:为什么 Percolator 不需要持久化
2PC 需要持久化,是因为它在故障恢复时,必须得知 提交点的信息 和 所有参与者的信息。
所有参与者:Percolator 的参与者信息通过lock字段持久化在了 Bigtable 中,通过secordary指向primary这种巧妙的方式,解决了协调者的定位问题。
提交点信息:Percolator 的提交点是primary写入 Bigtable 的时刻。通过write字段就可以判断是否提交。
因此,Percolator 将需要持久化的部分保存在了高可用的 Bigtable 存储上,从而同时保证了 Percolator 不需要单独持久化组件的同时,保证协调者的高可用。
3.6.5 一些思考:崩溃恢复的阶段在哪
Percolator 将崩溃恢复阶段放到了快照读的过程中。快照读时,如果发现[0, start_ts]时间戳上带锁,Percolator 会判断上一个事务是否完成,是否崩溃,是否提交,并对 primary和secondary行进行相应的操作,从而保证在Prewrite阶段前,崩溃恢复完成。
3.7 TiDB/KV 对 Percolator 的优化
3.7.1 Parallel Prewrite
本质是 Batching 优化,分批并发地进行 Prewrite
3.7.2 Short Value
本质是减少 I/O。对于 Percolator,会先读取write列,根据里面的时间戳再读取data列数据。如果数据本身很小,直接存在write列就不用读两次了
3.7.3 Point Read Without Timestamp + Single Region 1PC
单点读不涉及跨行事务,直接不用 timestamp,直接 1PC 本地执行事务即可。
如果涉及多行事务,但是这些行都在单个 Region 内,还是需要获取 timestamp 来保证 SI ,但可以直接 1PC。
3.7.4 Calculated Commit Timestamp(转)
在可重复读快照隔离级别,commit_ts 需要确保其他事务多次读取一样的值,因此可以直接算出来:
max{start_ts, max_read_ts_of_written_keys} < commit_ts <= now
由于max_read_ts_of_written_keys <= max{region_i_max_read_ts} + 1,那么有:
commit_ts = max{start_ts, region_1_max_read_ts, region_2_max_read_ts, ...} + 1
3.8 总结
3.8.1 任务分解的创新
- Percolator 将 2PC 分解为持久化的部分和非持久化的部分
- 持久化的部分记录了 Percolator 故障恢复所需的所有信息
- 非持久化的部分放在 Percolator 上,使得它是一个无状态的中间层
- 崩溃恢复的部分分解到了快照读的过程中
3.8.2 提交点的创新
- Percolator 将多行事务分解为
primary和secondary secondary提交的状态以primary为准- 提交点是
primary单行事务完成的瞬间,保证了其原子性和高可用。
3.8.3 并发控制的创新
- 通过 Bigtable 时间戳实现存储层面多版本
- 通过 TSO 实现并发层面多版本
- 通过
lock字段实现并发控制和故障恢复 - 通过
write字段实现快照读。