F2: Designing a Key-Value Store for Large Skewed Workloads 论文阅读
1. 摘要
1.1 背景
有两种 key-value stores 的范式
- 面向磁盘,专注于把设备 IOPS 打满
- 面向内存,专注于高吞吐和高可拓展性
这两种范式都不能满足当今的需求:在远大于内存的数据集上,进行高性能的读写。
1.2 工作
提出了$F^2$,一种 key-value 存储。
分区机制: 将空间分为了Stable,Read-Only 和 Mutable 区域
冷热分离: 写冷数据存在冷日志,写热数据存在热日志,读热数据存储在读缓存
实验结果:
- 能够在低的磁盘读写放大水平下,充分利用磁盘和内存带宽,达到高吞吐量
- 通过latch-free数据结构,实现高并发下可扩展性,并达到高吞吐量
- 在内存资源稀缺时的情况下,做到吞吐量的 SOTA
1.3 介绍
传统 KV 存储的设计
- 设计权衡: 针对磁盘进行优化,关键是明智地使用内存,利用磁盘带宽。
- 数据组织: 内存存热数据,磁盘存实际数据。
- 一些案例: RocksDB 和 Cassandra 都是用 LSM。
- 使用场景: 点查和区间查,但是需要维护偏序,导致吞吐量不高
作者认为在缓存(Cacheing)场景,现代 KV 有以下特征
- 设计权衡: 针对内存进行优化,并通过优化磁盘访问,在工作集比内存大时支持高吞吐
- 数据特征: 典型 skewed workload,存在一小部分的热点数据,大部分的 CURD 都落在热点上
- 数据组织: 大部分在活跃数据在内存,工作集可能比内存大
- 使用场景: 点查,更新,插入,并优先考虑高吞吐量
- 一些案例: FASTER
FASTER 的不足
- 对工作集大于内存的情况支持不好:哈希索引占内存太多
- 没有很好的区分冷热数据,优化内存使用
- 数据倾斜可能导致读写过程中,磁盘的读写放大
- 由于工作集大于内存,大量热更新被刷盘,造成不必要的磁盘开销和写放大
- 大量冷记录达到日志开头,并定期压缩到日志尾部,增加了日志尾部的数据竞争和写放大
$F^2$的设计创新
- 设计目标: Latch-free,工作集大于内存,善于处理高度倾斜的数据集的,混合键值存储
- 架构设计: 热日志索引,热日志,冷日志索引,冷日志,读缓存
- 冷热分离: 将写冷数据分到冷日志,将读热数据分到读缓存。
- 空间优化: 冷日志索引使用稀疏二级索引,大幅降低内存占用
2. FASTER 键值存储
2.1 无锁哈希索引
FASTER 的核心是一个无锁哈希索引,索引数据全在内存中。有$2^k$个缓存行大小的桶,细节如下。
struct bucket_t {
record_t *entry[7];
bucket_t* next; // next bucket address
};
struct header_t {
bool tentative_bit: 1; // cas satefy
short tag: 15; // speed up search
}
struct record_t {
header_t meta : 16;
record_t *prev : 48; // becomes a hash chain
std::string key;
std::string value;
};
FASTER 有四个基本操作:Read、Upsert、RMW(Read-Modify-Write)和 Delete。使用 Latch-free 算法添加删除哈希表中的条目,以及在记录链表中追加条目。每个指针都在内存中占 8 字节。FASTER 还支持 Resize。
2.2 The Epoch Framework
背景
FASTER 使用 Epoch 保护框架来保证多个线程间的延迟同步。允许我们在纪元到达安全状态时执行全局行动的能力,比如将 Hybrid Log 的只读区域刷盘,或者对 Hybrid Log 进行截断。
原理
- 我们有一个全局的计数器$E$,称为当前纪元。同时,每个线程维护一个 thread-local 的计数器$E_i$。所有$E_i$都存储在一个共享纪元表中。
- 线程周期性刷新$E_i$来与$E$同步。当所有线程的$E_i$都比某个纪元$c$大时,$c$被定义为安全的,所有小于$c$的纪元也是安全的。
- 我们还维护一个全局计数器$E_s$,它追踪当前最大安全纪元。整个系统维护以下不变量$E_s<E_i\le E$。
触发器
Epoch 框架允许我们在纪元到达安全状态时执行全局行动的能力。当纪元从$c$到达$c+1$,线程可以额外关联一个动作,当$c$安全时将会被触发。这个机制使得所有线程达成某个全局视图(达成共识)时,执行一定的动作。
接口
Acquire():添加$E_T$到全局纪元表中,并更新$E_T$到$E$Refresh():更新$E_T$到$E$,更新$E_s$到最大安全纪元,并触发回调BumpEpoch(Action):将$E$从$c$递增到$c+1$,并添加Action到回调列表Release():将$E_T$项从全局纪元表中移除
线程生命周期
Acquire将自己添加到纪元机制中- 发出一连串用户操作,并定期调用
Refresh - 调用
CompletePending来处理之前没有处理的操作 - 调用
Release将线程从纪元注册表中注销
2.3 Append-Only 日志存储
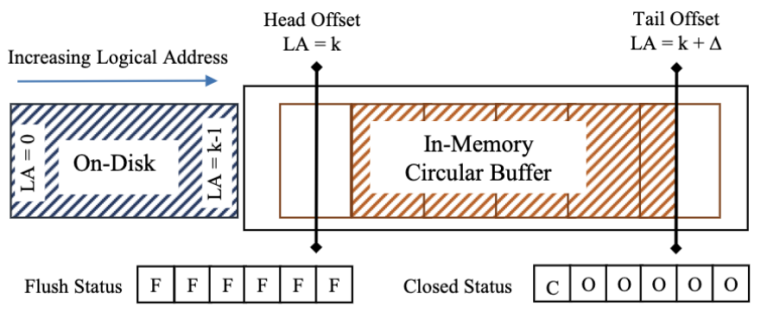
逻辑地址空间
使用日志结构存储,横跨内存和二级存储,逻辑地址(Logical Address,LA)空间从0开始。低地址存储在磁盘上,高地址存储在内存中的环形缓存中。环形缓存区存放了多个固定大小的页帧,每个页帧大小为$2^F$字节。页帧是刷盘的基本单位。在磁盘中对应着一个日志页。
持久化
我们需要使用无锁的方式将环形缓存区中的数据刷盘。
flush-status:追踪该页是否已经刷盘closed-status:追踪该页是否可以清理,以被重用
刷盘: 当日志尾进入新页$p+1$时,调用BumpEpoch(Action),动作为:发起异步I/O请求,将页$p$刷盘。刷盘成功后,设置该页的flush-status为F(Flushed)。
由于头偏移量跨越页边界时,会调用
Refresh(),安全时才会触发回调,以确保页$p$刷盘是安全的。
清理: 当日志不断追加时,需要重用环形缓存头部。环形缓存区头部往前时,先将头部偏移量递增,然后调用BumpEpoch(Action),动作为:设置该页的closed-status为C(Closed)。在清理页面前,必须确保数据已经刷盘。
线程看到该页的状态是
C,当且仅当到达了一个安全的纪元。
2.4 Hybrid Log 日志存储
Region 分段
日志本身被分为三个连续的区域,从尾部到头部依次是:
- 可变区域
Mutable:位于内存,支持原地更新(in-place update) - 只读区域
Read-Only:位于内存,只能通过 RCU(Read-Copy-Write) 来更新(out-of-place update) - 稳定区域
Stable:位于磁盘。只能通过 RCU 来更新。
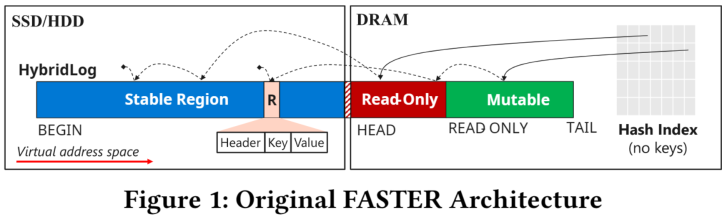
- 相当于在 Append Only 日志存储的基础上进行了拓展,加入了段式管理的思想
- 段空间通过上述四个偏移量维护,如图1所示。
READ_ONLY偏移量前的数据可以刷盘。
安全只读偏移量
READ_ONLY偏移量的修改可能对其他线程不可见。更新操作不确定是执行 RCU 还是 原地更新,盲目选择其中一种会导致更新丢失,导致并发安全问题。因此引入安全只读偏移量。
- 它追踪所有线程可见的只读偏移量中最小的
- 只读偏移量更新时,调⽤
BumpEpoch(Action)注册回调 ,动作为更新安全只读偏移量到新的值。 - 当动作被执行时,将触发安全只读偏移量的更新
- 当地址小于安全只读偏移量,键值对的更新需要 RCU。
Fuzzy Region
引入安全只读偏移量后,在线程的视角中,出现了Fuzzy Region。 每个线程中的“安全只读偏移量”和“只读偏移量”会有滞后,因为线程可能没有及时刷新。
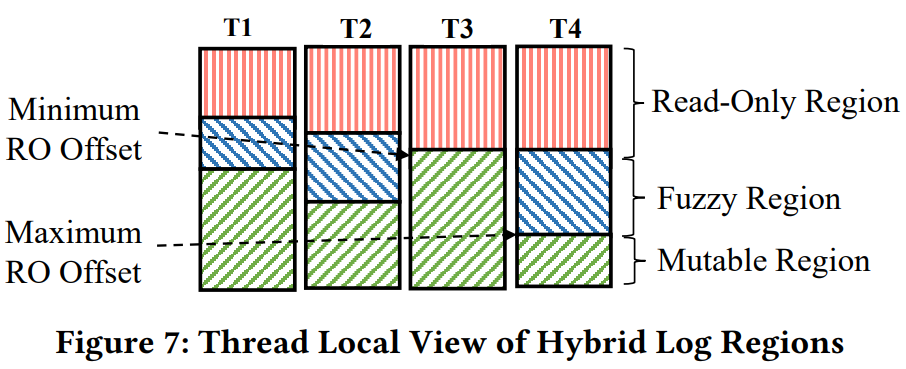
不同写入操作对 Fuzzy Region 会有不同的动作,总的来说如下表。其中 CRDT(Conflic-free Replicated Data Type)是一种无冲突复制数据类型,副本可以独立并行更新,不需要再副本间协调。

特别之处在于 RMW 操作不能之间 RCU,因为在 Fuzzy Region,不确定是执行 RCU 还是 原地更新,盲目选择其中一种会导致更新丢失,导致并发安全问题。解决方法:
- 延迟处理: 等到不在 Fuzzy Region 再进行处理
- 具体实现: 将更新操作放到 Pending List,延迟执行。确定安全后再执行。
缓存特性
- 缓存驱逐协议: Hybrid Log 本质上是新的缓存驱逐协议,很像
Second-Chance FIFO。但是它做到了键值对粒度的控制,而且开销较小。 - 原地更新: 在有热点且写高负载情况下,日志大小不会很快增加(由于
Mutable原地更新的特性) - 持久化: 宕机时,Hybrid Log 没有刷盘的地方会丢数据
- 模糊检查点(Fuzzy Checkpoint): FASTER 异步读取散列索引,但由于并发更新,这个检查点是模糊的。
日志压缩
FASTER 使用基于扫描的方式进行日志压缩:扫描整个日志,并将日志的第一部分的存活记录保存在一个临时的内存哈希表中。最后,这些存活记录会被插入到 Log 的尾部,紧接着 BEGIN 地址可以往前移动。缺点有:
- 需要扫描整个日志,并且用额外内存来维护一个临时哈希表。
- 增加了日志尾部的争用,因为压缩的冷写记录会和更新操作产生竞争,导致性能下降和更高的写放大。
3. $F^2$整体设计
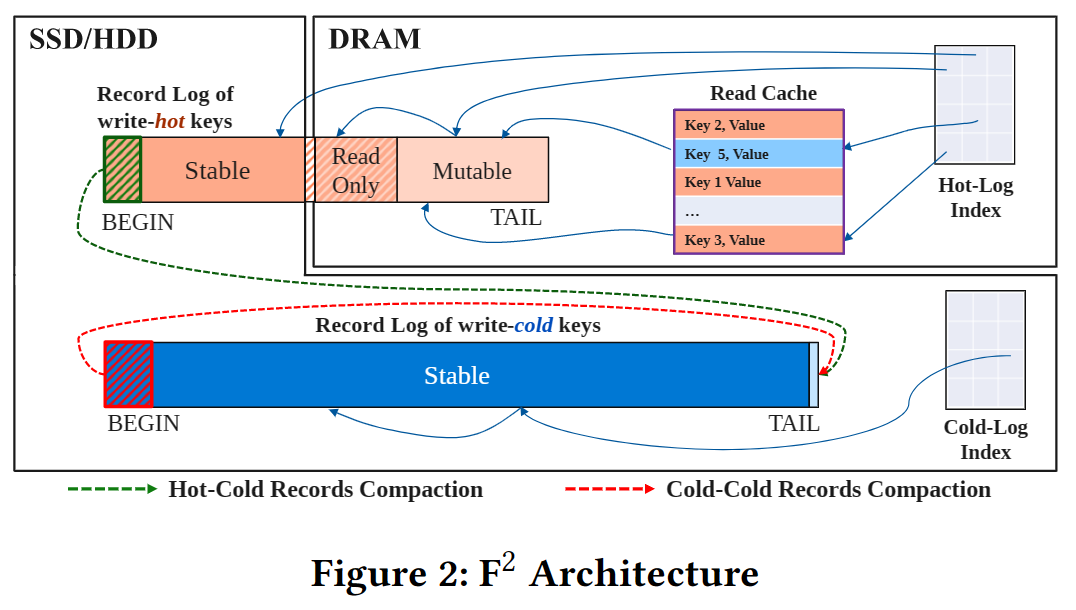
关键点
- 将冷热记录物理隔离,根据记录的读热度和写热度,将记录放在不同的组件上。
- 写热记录存储在热日志中,并使用热日志索引加速查询。热日志跨越内存和磁盘,热日志索引仅在内存中。
- 写冷记录存储在冷日志中,并使用冷日志索引加速查询。冷日志只保留在磁盘,冷日志索引跨越内存和磁盘。
- 冷日志和热日志的读热记录存储在读缓存中,并借用了热日志索引加速查询。
- 使用这种分层日志结构,可以为读/写,冷/热四种数据组合提供高性能的同时,提高内存利用率。
3.1 组件总览
热日志索引(Hot-Log Index)
- 目标: 只对热日志进行索引
- 思想: 用的和 FASTER 一样
热日志(Hot-Log)
- 目标: 使写热记录能够快速的并发检索和更新
- 思想: 它是 Hybrid Log 实例,只有压缩行为和 FASTER 不同。
冷日志索引(Cold-Log Index)
- 目标: 减少写冷记录所需的内存量。
- 思想: 稀疏二级索引 + Hyper Log 存储
冷日志(Cold-Log)
- 目标: 实现写热,写冷记录的物理分离。
- 思想: 和热日志用的 Hybrid Log 相同,但是只有
Stable区域,所有数据都驻留在磁盘上。
读缓存(Read Cache)
- 目标: 优化读热记录的读取
- 思想: 索引借用热日志索引,存储用 Hyper Log,驱逐使用
Second-Chance FIFO。
3.2 用户接口
Read:简简单单的读取Upsert:替换原来的值,或者插入新值。Delete:插入墓碑记录,逻辑上删除。RMW(Read-Modify-Write):输入现有值或默认值,根据用户逻辑,原子更新一个值。
有些操作并不会⽴即完成,而是返回PENDING状态。线程会周期调⽤CompletePending来完成这些操作。
3.3 记录的生命周期
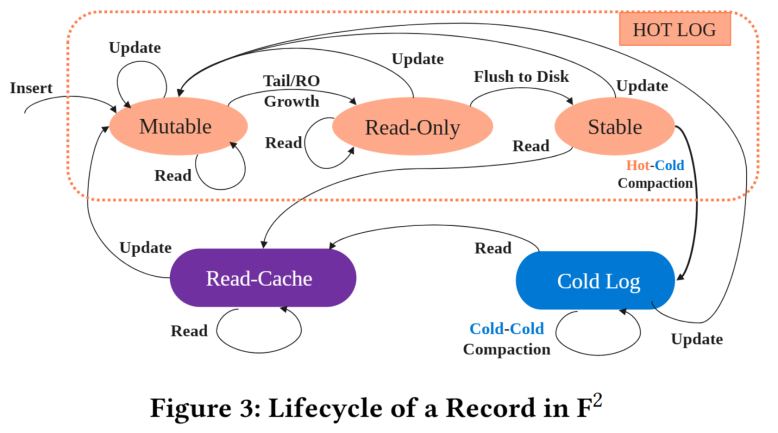
当用户插入一条(key, value)数据时,记录的生命周期如下:
- 刚开始,记录会追加(Append)到热日志
Mutable区域,支持原地更新。 - 随着其他记录追加到日志中,我们的记录最终会移动到
Read-Only区域,不支持原地更新。更新时会执行RCU操作(Read-Copy-Update),将更新的记录追加到热日志Mutable区域。 - 当我们的记录在内存中时,不使用读缓存。
- 当驻留在
Read-Only区域的记录一段时间没有更新时,它会刷到磁盘中,成为Stable区的一员。读取会先读到读缓存,更新需要执行RCU。 - 如果没有进一步的更新,我们的记录最终会送到热日志的头部。随着更多记录被插入,热日志的大小就会越来越大,那么就需要通过冷热压缩,将写冷记录从热日志搬到冷日志。
- 热日志开头的活动记录被复制到冷日志的尾部
- 一旦复制成功,热日志将会被截断,压缩区域的所有记录都会失效
- 压缩过程中,热日志的尾部保持完整。
- 一旦冷热压缩完成,记录实际存储在冷日志中。事实上,由于热点数据只占总数居的一小部分,所以大部分数据最终在冷日志中。读取时,先读到读缓存。更新时,采用
RCU的策略,使其变成热日志。 - 如果仍然没有进一步的更新,我们的日志会跑到冷日志头部。对于不存活的日志(具有删除墓碑),我们需要进行垃圾收集,这个时候会发生冷冷压缩
- 活的冷日志记录从头部复制到尾部
- 压缩成功后截断冷日志头部,压缩区域的所有记录失效
- 所有不存活的记录将最终从$F^2$中完全删除
4. 分层混合日志架构
4.1 基于查找的压缩
背景:$F^2$基于冷冷和热冷压缩不断压实日志。传统日志压缩算法需要扫描整个日志来识别存活记录,内存开销和计算开销都很大。
思想:通过哈希索引判断存活。
做法:给定源日志和目标日志,它由两个阶段构成
- 复制阶段: 扫描
[BEGIN, UNTIL]区域,这个区域表示特定比例(比如10%)的日志。对于每个记录,我们使用 条件插入 操作判断它是否存活,存活的日志可以被复制。 - 截断阶段: 一旦我们扫描完上述区域,我们通过
CAS(BEGIN, UNTIL)对源日志进行截断,并删除索引,释放空间。
条件插入(ConditionalInsert)
- 目的: 保证压缩记录不会覆盖同一记录下的较新副本
- 语义: 给定一条
(key,value)记录和START日志地址(Log address)。条件插入操作将记录追加到目标日志,当且仅当源日志的(START, TAIL]范围内不存在与key匹配的记录。 - 实现: 假设
START地址和即将要被压缩条目的日志地址匹配。- 首先,我们会去源日志索引中查找我们
key对应的record_t* entry。 entry是源日志中最新记录的日志地址,并形成了一条哈希链。- 从这个
entry开始,扫描哈希链(可能会触发I/O)。如果在扫描过程中没遇到与key匹配的记录,我们就可以准备将记录拷贝到目标日志中。
- 首先,我们会去源日志索引中查找我们
- 冷冷压缩可能导致更新丢失: 冷冷压缩期间,必须保证再次期间没有同一个记录正在追加到冷日志,不然会导致更新丢失问题。解决方法:先更新日志,再更新索引。我们先追加到日志尾部,然后使用
CAS更新索引。如果更新失败,说明过程中有别的元素插入了,需要invalidate刚刚写入的日志,并进行重试。 - 热冷压缩不会导致更新丢失: 因为冷日志一定属于较旧的写入,不会说新的记录覆写了旧记录。
- 好处: 内存效率极高。FASTER 需要追踪压缩区域的所有记录,而$F^2$只追踪其中的一小部分。判断存活效率高。FASTER 需要扫描整个日志来推断记录是否存活,而$F^2$只需要检索对应的哈希链。
多线程日志压缩
由于条件插入操作时天然支持并行的,本章只需关心我们如何协调线程,使得日志压缩也能并行。 在日志压缩期间,我们永远只操作一小块需要压缩的日志区域$C$,我们使用一个环形缓冲区来维护这个区域,它由固定大小的帧(Frame)组成,每个帧可以存放着一个日志页面(Log Page)。
- 以帧为单位协调日志压缩
- 帧内使用多线程进行处理
- 通过 Epoch 框架来做延迟同步,来做内存释放和预取的工作。
配置
基于查找的压缩作为一个后台线程不断运行,可以指定:
- 冷热日志的磁盘预算: 用于热冷压缩和冷冷压缩
- 触发压缩的百分比: 达到阈值的百分之多少开始进行压缩
- 压缩区域百分比: 压缩区域占整个日志的比例
4.2 单点操作
盲目更新/删除
- 更新首先查找热日志索引
entry,把新记录追加到热日志尾部,最后CAS更新索引指针。 - 如果
CAS更新失败就进行重试。 - 删除相当于插入墓碑。
读取
- 首先在热日志中进行读取,如果读到墓碑,返回
NOT_FOUND。 - 如果读不到,就去冷日志里面读取,逻辑类似。
- 冷冷压缩和读缓存的情况需要特殊处理。
RMW 操作(Read-Modify-Write)
定义:对某个key,给一个当前值或默认值,按照这个值通过一定的逻辑更新为新值。
- 首先,定位最近的一个匹配的
key对应的value - 如果位置处于热日志
Mutable区域,那么可以通过CAS进行原地修改 - 否则,需要进行
RCU,整体步骤如算法1所述。

4.3 一些异常情况
冷日志读取时,先通过冷日志索引找到对应的record_t* entry,沿着哈希链向后遍历找到对应的记录。然而,有可能出现记录确实存在于冷日志中,遍历时却找不到的现象。(如图4,冷冷压缩导致遍历过程中,无法遍历到R1)
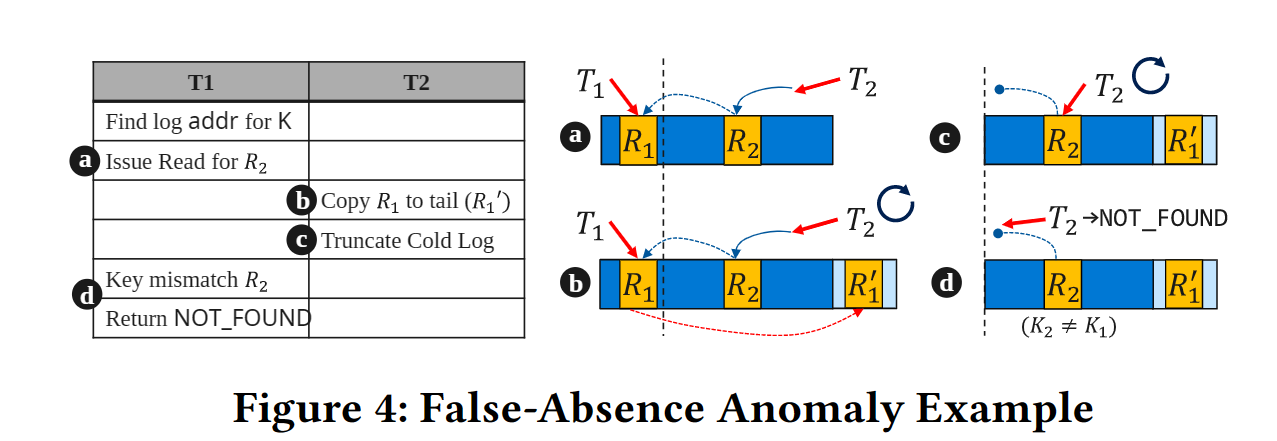
解决方法:思想是乐观读。冷日志中引入一个共享的原子计数器num_truncs追踪日志的截断次数。如果读取前后,num_truncs发生了变化,说明存在日志截断,那么对新增的部分再重新进行扫描即可。
5. 冷日志索引
背景:冷日志很多,索引很占内存空间,希望查询快的同时,内存占用少。
思想:两级索引。将多个哈希索引条目组合成哈希块,存储在磁盘中。key先定位到哈希块,再从读缓存或磁盘中读取哈希条目,最后从哈希条目中定位到冷日志地址,读取记录。
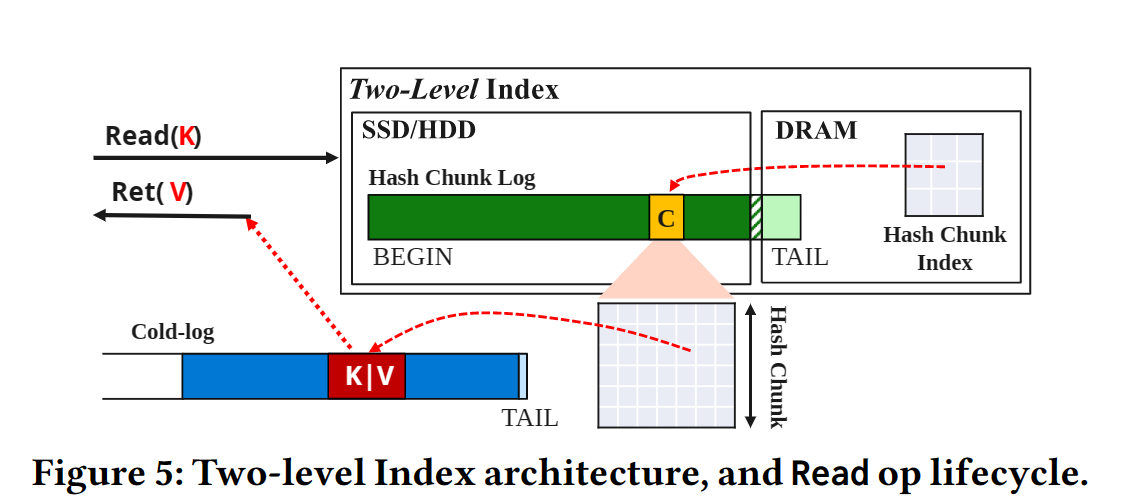
5.1 索引组织形式(Index Organization)
思想: 多个哈希索引条目组合成哈希块(chunk),哈希块存储在 Hybrid Log 上。
- 哈希块有一个唯一 ID,每个块包含$2^k$个哈希条目,每个哈希块大小相同。
- 日志结构存储在内存或磁盘上。内存上的部分支持并发。
5.2 索引操作
查找
h=hash(key),前面几位作为chunk_id。- 根据
chunk_id定位哈希块日志中的哈希块(可能产生磁盘I/O) - 用后面几位作为
chunk_offset,找到对应哈希链record_t* entry。 - 扫描这条链,找到最新的记录
更新
- 先查找,如果哈希块不存在,先初始化一个哈希块(里面的条目都是空)。
- 发起
RWM操作。 - 并发更新可能会导致问题:两个线程1,2同时
RWM,但是可能第二个线程覆写了最终的记录,第一个线程的更新丢失。解决方法:乐观读,如果原值被修改需要重试。
5.3 索引配置
- 哈希块大小: 256B,即每个块 32 个哈希链。
- 哈希块个数: 和冷数据基数差不多
- 内存预算: 冷日志索引在内存中的最大值
6. 读缓存(Record Read-Cache)
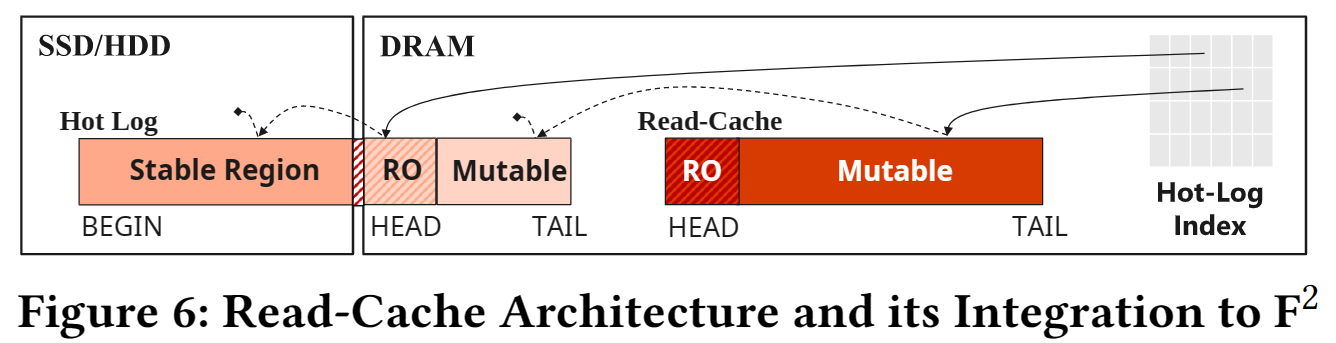
6.1 读缓存架构
- 一个 HybridLog 实例,仅包含
Mutable和Read-Only区域。 - 类似
Second-Chance FIFO策略维护缓存。 - 对于某个
key,读缓存总是指向最近的记录。 - 读缓存的索引借用了热日志索引进行维护。
- 热哈希索引链的地址可能执行热日志或读缓存
- 哈希链中,最多只有一条记录在读缓存。
6.2 Upsert,RWM,Delete
插入新记录时,先清读缓存(设置失效位),再进行插入
6.3 Read
- 先在热日志索引中查找,如果在内存或者读缓存中找到记录,就返回。
- 如果数据位于热日志
Read-Only区域,更新读缓存(因为它很快要在磁盘上了)。 - 如果数据在磁盘中(无论是在热日志,还是冷日志),先更新读缓存,再返回数据。
6.4 Second Change FIFO 介绍
- 维护一个循环队列,每次清理访问标志位为 0 的页面,每次访问后将标志位置为 1
- 这样只要周期内页面有访问,就会免遭清理,除非所有的页都为 1。
6.5 Eviction
- 驱逐以页为粒度进行。使用类似
Second-Change FIFO算法。 - 对于一页中的每个记录,先确定它的标志位是否为 0,代表近期是否有被访问过,如果标志位为 1 就跳过。
- 否则记录需要被驱逐。我们需要在热日志哈希索引中移除这个缓存项。
- 由于图6,读缓存的下一项必定不在读缓存,因此通过
CAS就可以移除缓存项了
7. 个人总结
- 个人认为的创新点在与冷热分离、原地更新的日志设计、和 EPF(Epoch Protection Framework)。
- 其中 EPF 和 Hybrid Log 来自 FASTER,冷热分离来自$F^2$。
- 个人认为整个系统能实现 Latch-free 的关键是 EPF 和 无锁哈希索引。EPF 的思想很多数据库都有用到,哈希链的无锁化思想来源于 Lock-free linked lists using compare-and-swap 这篇论文,感觉比较经典。
- Hybrid Log 在设计上如此快,一部分原因是舍弃了全序关系和一部分持久性。它不支持范围查询,并且
Mutable区域没有做 WAL,也没有落盘,可能导致数据丢失,但是这种 in-place 和 out-of-place 数据结构的结合是一种很优秀的思想。 - 冷热分离感觉是论文最大的亮点,按照读写的热度将数据分为4类,通过精心设计的日志压缩实现数据的流动,我觉得是本文最有借鉴意义的地方。