Flink State Backend:调研,工业实践与优化
1. 背景
1.1 按用途分类
- OperatorStateBackend: 存与计算逻辑无关的数据,如 Kafka Offset,体量比较小,不受数据规模和计算逻辑影响
- KeyedStateBackend: 存与计算逻辑强绑定的状态数据,大小受数据规模和计算逻辑影响,大小可能非常大
1.2 按实现分类
| StateBackend | in-flight | checkpoint | 吞吐 | 推荐使用场景 |
|---|---|---|---|---|
| MemoryStateBackend | TM Memory | JM Memory | 高 | 开发与调试、对数据丢失或重复不敏感 |
| FsStateBackend | TM Memory | FS/HDFS | 高 | 普通状态、大窗口、KV 结构 |
| RocksDBStateBackend | RocksDB on TM | FS/HDFS | 低 | 超大状态、超长窗口、大型 KV 结构 |
MemoryStateBackend(默认)
特性
- 数据存储在 Java 堆上
- 支持异步快照,避免主数据处理流程的阻塞
- 进行 Checkpoint 时,状态后端会对当前状态进行快照,并将其作为 Checkpoint ACK 消息的一部分,发给 JobManager。JobManager 将这个快照存储在堆上。
局限性和适用场景
- 单个状态不能超过 akka 帧大小(默认 5 MB)
- 状态大小不能超过 TaskManager 内存
- 聚合状态必须能够在 JobManager 内存中放的下
- 不能生产上使用
FsStateBackend
特性
- 支持 HDFS 或 本地文件系统
- 状态会先存储在 TaskManager 的内存中
- 支持异步快照
- 在 Checkpoint 时,会将状态快照写入对于的文件系统中,同时在 JobManager 中存储存储少量元数据。
局限性和适用场景
- 状态大小不能超过 TaskManager 内存
- Checkpoint 需要全量写入数据,开销较大
- 可以生产上使用
RocksDBStateBackend
特性
- 数据跨越内存和本地磁盘
- 不支持异步快照(因为快得很,不需要这个特性)
- 支持增量快照(仅需要上传新生成的 sst 文件)
- 单 key 最大 2G
局限性和适用场景
- 性能相较上面两者(数据全在内存)较低
- 状态需要序列化和反系列化,以跨越 JNI 边界
- 非常适合 HA 方案,适合大状态,长窗口的有状态处理任务
1.3 Checkpoint 机制
Aligned Checkpoint 制作过程(本质是 Chandy-Lamport)
- JobManager 的 CheckpointCoordinator 向所有 Source 算子周期性插入 Checkpoint Barrier
- Barrier 上面带有编号,用于标识 CheckpointID
- Source 算子收到 barrier 后:
- 暂停发出记录,通知状态后端生成 snapshot,同时把 barrier 发给下游
- snapshot 制作完毕后,给 JobManager 发确认消息
- 当 barrier 全部发送完毕后,恢复工作
- 普通算子收到 barrier 后:
- 等待它的其他上游也发过来这个 barrier
- 没收到 barrier 的 channel 数据正常处理数据
- 收到 barrier 的 channel 新到来的数据会先缓存起来,不能处理
- 等 barrier 到齐后,通知状态后端生成 snapshot,同时把 barrier 发给下游
- 所有 barrier 发出后,就会开始处理缓存的记录
- 处理完缓存的记录就可以继续处理输入流
- Sink 算子收到 barrier 后:
- 等所有 barrier 都到齐
- 到齐后,将自身的状态写入 checkpoint
- 随后向 JobManager 确认已接收 barrier
- JobManager 确认 Checkpoint 制作完成,会保存与这次 Checkpoint 相关的元信息
Checkpoint + 2PC Sink 怎么确保 End-to-end Exactly-once
- Prepare: on last checkpoint finished(or system started)
- Commit: on current checkpoint finished
- Checkpoint 保证不丢,2PC 保证不重
Checkpoint 高可靠
- 实践中,一般采用 RocksDBStateBackend 作为状态后端
- 执行 Checkpoint 时,会让 RocksDB Memtable 刷盘,生成 L0 层文件,期间可能有 Compaction
- 刷盘 和 Compaction 产生了文件变动,这些变动的文件就是增量 Checkpoint
- Checkpoint 高可靠需要 JobManager 高可用 和 存储高可靠
- 存储高可靠通过把 RocksDB 部署到分布式文件系统达成(或同步数据到 DFS)
- JobManager 高可用需要 Zookeeper 来管理元数据 + 自动重启(或主备)
1.4 工业界的优化与实践
- 资源利用和分布式 Rescale: RemoteStateBackend 做存算分离
- 大 KV 和性能突刺: LocalStateBackend 相关优化
- Checkpoint相关优化: 更轻量,更快速
2. Bilibili 实践:RemoteStateBackend
2.1 RocksDBStateBackend 缺陷
- 磁盘利用率低: B站 80% 的任务都是 100GB 以内的小状态 或者无状态任务,这些机器的磁盘利用率低。
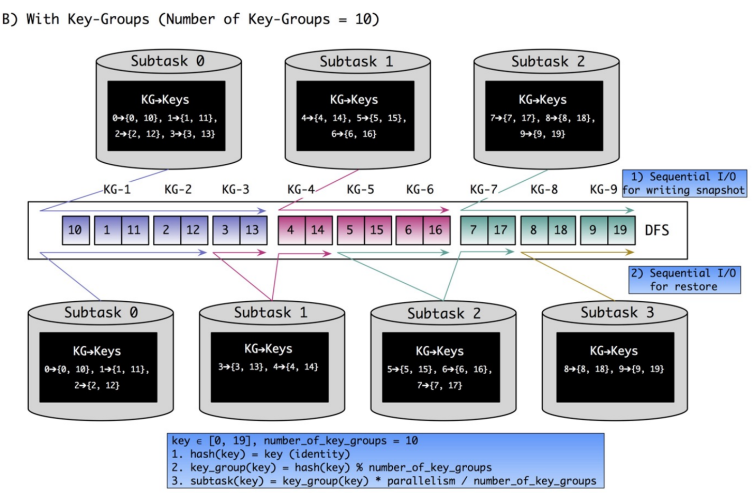
- 大任务 Rescale 慢: 超大 State 在 Rescale 时,任务会先把数据下载到本地,然后实例化成 RocksDB。TaskManager 再根据 KeyGroup 做 Rebalance 操作,本质是 RocksDB 根据 KeyGroupId 做 Seek 和 BatchWrite 操作,成本比较大。
那么解法很明显,把 RocksDB 整合起来,变成资源池,进行存算分离。Flink 直接在分布式存储上面操作。
2.2 解决方法:RemoteStateBackend
B 站用自研的 Taishan(基于 RocksDB 和 SparrowDB)代替了 RocksDB,它是一个分布式KV存储,支持水平扩容,在线升级,解决了1,2两点。
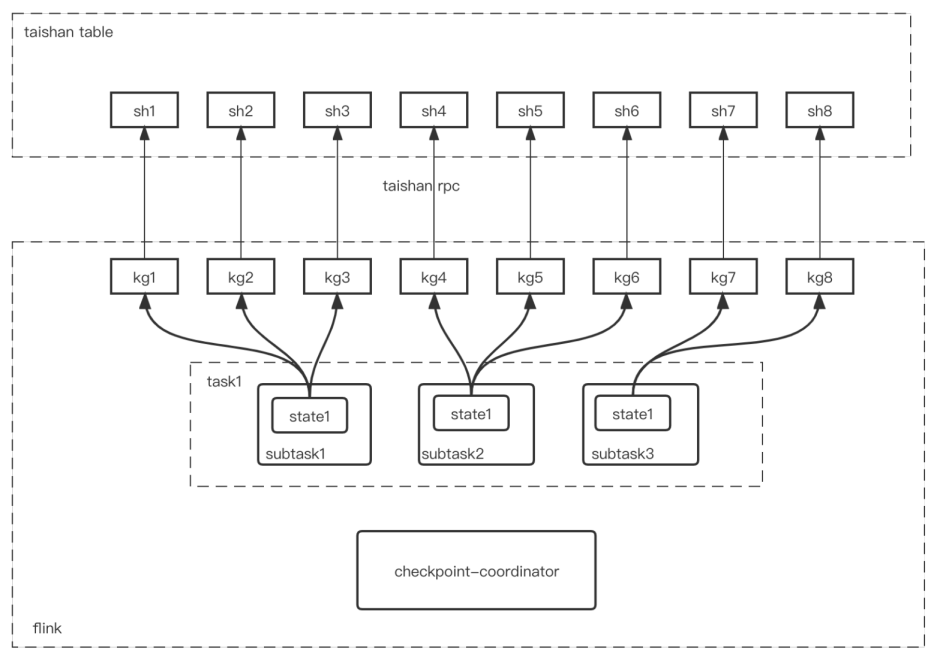
架构设计关键点
- Taishan 存储有 Shard 概念,支持分裂合并。
- KeyGroupId 和 ShardId 一一对应
- Taishan 表的 Shard 分片数 和 Flink 的 maxParallelism 保持一致,不能分裂合并
- 任务第一次启动,每个带有 KeyedState 的 Operator 会创建一张 Taishan 表
- 一个 Operator 可能存在多个 State,发送的 KV 数据中,K 会带上 ColumnFamily 前缀
- Flink 做 Checkpoint 时,会对 Taishan 每个 Shard 做一次 Snapshot,每个 Shard 的 SnapshotId 相同。
- Flink 做任务恢复时,根据 Taishan SnapshotID,对每个 Shard 做数据恢复的工作
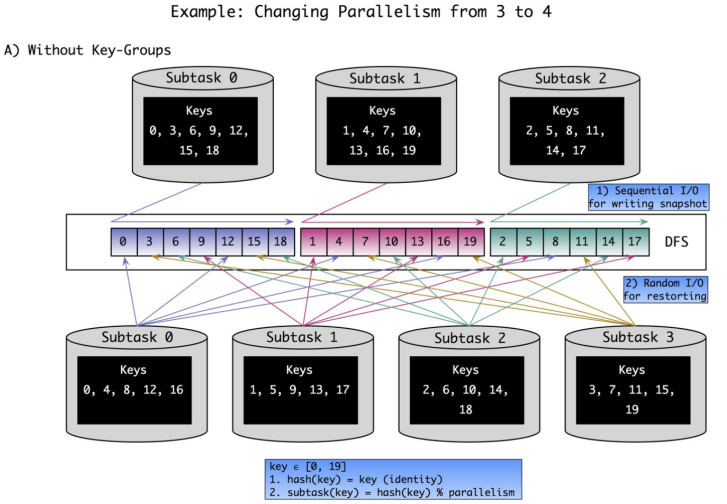
数据分片
- KeyedState 分片逻辑不变
- 有限的 Rescale 能力,本质是分片 KeyGroup 在 Subtask 之间移动,分片无法分裂
- 多个 KeyGroup 存储在相同 RocksDB 的 ColumnFamily 中,依赖 RocksDB 的有序性。Rescale 过程按照 Range 分片。
优势
- 更轻量级的 Checkpoint: RocksDBStateBackend 在做 Checkpoint 时,会根据 SnapshotStrategy 决定增量还是全量上传到 FileSystem,比较重。我们只需上传 metadata 元数据到 FileSystem 即可,单 Shard 的 Snapshot 在毫秒级别,很轻。
- 存算分离: 降低了 Flink 对磁盘的依赖,更云原生(但性能更差)
- 任务 Rescale 很快: RocksDBStateBackend 做 Rescale 需要数据迁移,而 Taishan 不需要,因为 KeyGroup 和 Shard 一一对应,只需修改 KeyGroupRange 的范围即可。
2.3 优化
背景
- State 每秒读写量: 最高百万 ops,平均十万多 ops。
- State 大小: Group/Window Agg 场景几十字节,Join 场景压缩后也有上百KB。
- 存算分离: 对网络和序列化需求很高,要尽可能降低读写 ops。
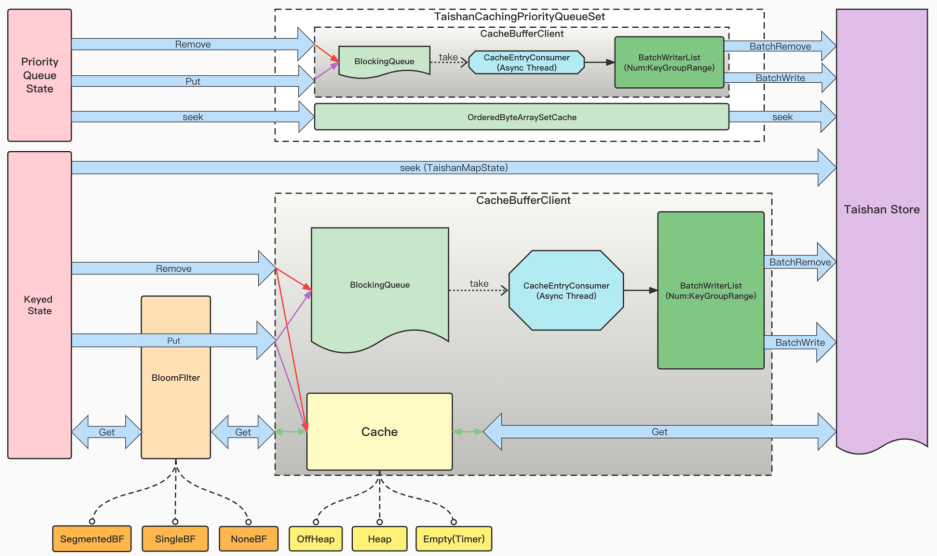
BatchWrite
- 将 put/remove 请求放到当前 subtask 的 BlockingQueue 中,到达一定大小或时间就刷到 Taishan 中
CacheRead
- 用 OhcHeapLinkedLRUMap,并关闭了 Rehash。
- 字节把 Cache 用在了 RocksDBStateBackend 上,也有一定收益
BloomFilter
场景: (1) Key 较为稀疏,大量 Read 为空;(2) Key 周期性变化,大量 Read 为空。
解决: Offheap BloomFilter
2.4 展望
- 高 QPS 场景: key 非常稀疏,导致非常多 Read 请求为空,BloomFilter 扛不住。
- 大 Key/Value 场景: 双流 Join 可能导致大 Key/Value,导致 WriteStall。
- 分层存储: 参考 Tiered State Backend,将机器上的磁盘内存资源都用作缓存,状态数据保留在远端存储。
3. 字节实践:LocalStateBackend(with TerarkDB)
3.1 背景
需求
- 状态在几十到上百字节
- 单 Task 实例在上百 MB
- 需要支持 TTL 清理过期数据
问题
- 大 KV 写放大严重
- 压缩占用 CPU,并且影响 Checkpoint(因为 Checkpoint 强制落盘,触发压缩)
- 压缩无法清理过期数据
- Leveled Compaction:升序 Key 之间无交集,清不了
- Universal Compaction:全部文件都要找,开销太大了
- FIFO Compaction:按创建时间清数据,但文件都在 L0,读开销太大了
3.2 TerarkDB
面对以上问题,TerarkDB 的解决方案:
- 写放大: KV 分离(大KV) + LazyCompaction(中小KV)
- 资源利用率问题: FastCompaction
- Checkpoint落盘问题: 基于 WAL,并解耦 Checkpoint 和 Compaction
- 过期数据问题: Schedule TTL GC(估计是用分布式任务做的)
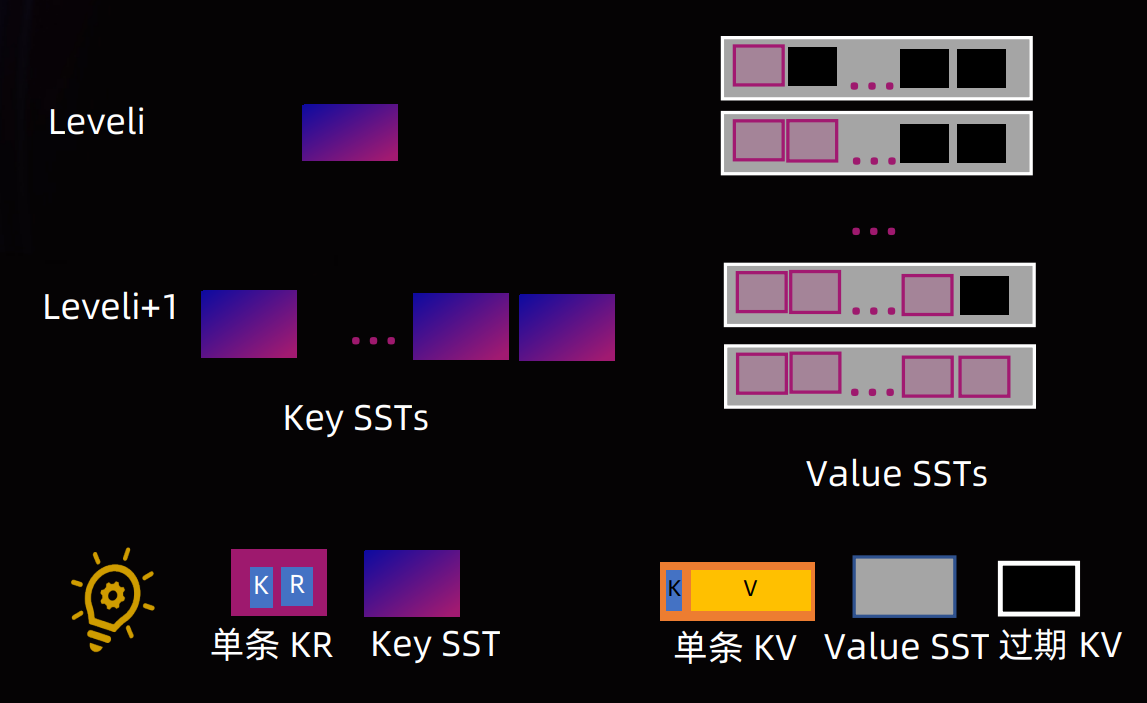
3.3 KV 分离
思想
- 在一个 Value Log 上面不断追加 Value,原始的 SST 中 Value 只记录对应的 Offset 即可。
- 把符合阈值的 Value 之间分离存储,从而降低 Compaction 和 Seek 开销
- 缺点:范围查询需要两次 I/O,性能低了。解决方法是小 Value 内联,大 Value 直接 __mm_prefetch。
| 维度 | Wisckey | TitanDB | BlobDB | TerarkDB |
|---|---|---|---|---|
| 分离条件 | always | 超过阈值 | 超过阈值 | 超过阈值 |
| Scan成本 | Value无序,Scan成本高 | Value 局部有序 | Value 局部有序 | Value 局部有序 |
| GC影响 | 锁前台I/O,开销高 | 锁前台I/O,开销高 | 影响小 | 影响小 |
| GC效率 | 滚动GC,效率高但对热数据不友好 | 总是选择垃圾最多的Blob,GC效率高 | Compaction 过程选择最老 Blob 进行滚动 GC,写放大大 | 总是选择垃圾最 多的 Blob, GC 效率高 |
| MergeOperator | T | F | F | T |
3.4 Lazy Compaction
Compaction 种类
核心: 在于合并时机,读写放大的权衡与选择。
- Leveled Compaction
- 全部层级从上到下进行层级合并
- 读写放大严重,但是空间放大低
- Tiered Compaction
- 即 RocksDB 中的 Universal Compaction
- 读放大和空间放大严重,但写放大最小
- Tiered+Leveled Compaction
- RocksDB 中的 Level Compaction
- 一种混合策略
- 空间放大比 Tiered Compaction 低,写放大比 Leveled Compaction 低
- Leveled-N Compaction
- 一次合并 N-1 层到第 N 层
- 合并开销大
- 相比 Leveled Compaction 写放大更低,读放大更高
Lazy Compaction 思想
核心: 虚拟 SST 数据结构,从而延迟合并,并提供更好的合并策略。
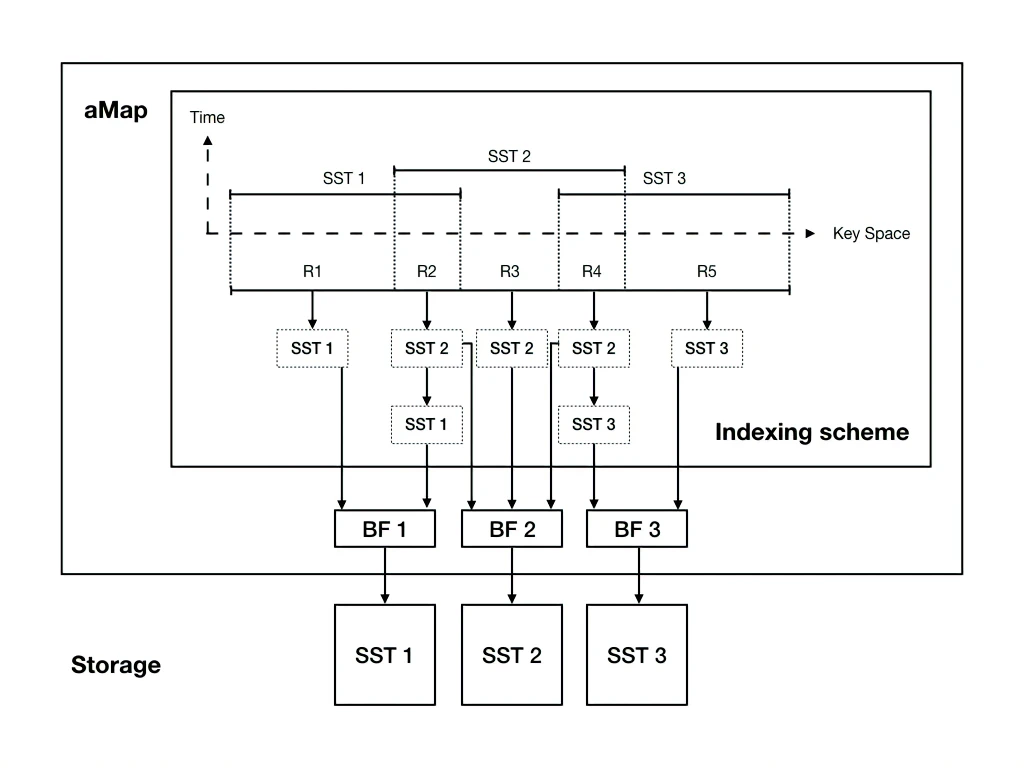
关键点
- 继承了 RocksDB 的合并策略(因为 SST 是虚拟的,对 RocksDB 透明)
- 当需要压缩时,会构建 Adaptive Map(aMap),将候选的 SST 组成新的 SST
- aMap 中会切分出多个不同的重叠段(如上图 R1,R2,R3,R4,R5)
- 后台 GC 线程选择重叠度最好的层进行实际的 GC。
- 降低了中小 KV 的写放大(为什么是中小KV:因为大 KV 都分离了)
3.5 LazyBuffer
有点类似 Netty 中的 CompositeByteBuf,减少I/O。实际思想和 Lazy Compaction 类似,通过一个虚拟层,替代 PinnableSlice 延迟 I/O 发生的时间,从而减少不必要的 I/O 开销。
3.6 Checkpoint&Compaction 优化
FastCompaction
- 利用弹性算力,进行分布式 Compaction
- 更快的 Compaction,更好利用分布式资源
WAL Checkpoint
- 类似 Flink 1.15 的 Generic Log-Based Incremental Checkpoint,但不是 Generic 的。
- 利用 WAL,Checkpoint 时只持久化 WAL,不进行 Compaction。
- 回放只需 Snapshot + WAL 回放。
- 只需增量上传 WAL 部分。
- 但问题也来了,WAL 积累下来还挺大的(没有给解决方案,估计交给另外一堆机器去做分布式Compaction)
- 减少 CPU 的周期性突刺和吞吐量突刺
新硬件
可以做 FPGA,QAT 来 off-load 压缩。用 NVM 或 KVSSD 做存储。
4. Generic Log-Based Incremental Checkpointing
4.1 发展历史
- Asynchronous Snapshot:主要解决 Snapshot 对 Task 的阻塞问题
- Incremental Checkpoint:主要解决全量 Snapshot 时间长,上传数据多的问题
- Unaligned Checkpoint:本质还是 Chandy-Lamport 算法,解决背压 Checkpoint 阻塞问题
- Buffer Debloating:Debloating 就是消胀。本质就是缩减 Inflight 数据(即在上下游中间的数据),降低 Distributed Snapshot 的存储开销
- Generic Log-Based Incremental Checkpointing(New):解决 Incremental Checkpoint 刷盘导致的压缩(可能导致吞吐量峰刺和write stall),减少需要上传的 SST 文件数量。
4.2 Aligned & Unaligned Checkpoint
本质上都是 Chandy-Lamport 算法。属于对 Chandy-Lamport 的一种实现。
- barrier 相当于 Chandy-Lamport 中的 marker,收到 marker 后:
- 向下游 output channel 发送 marker
- 记录自己进程的状态,开始记录所有上游 input channel 接受到的 message
- Aligned Checkpoint:barrier 和数据在一个 channel 内(受背压影响),先处理数据再处理 barrier。
- Unaligned Checkpoint:barrier 和数据在一个 channel 内流动,但是存在一种机制告知下游,channel 内存在 barrier。下游会把数据接收缓存起来,然后直接处理 barrier。
4.3 Incremental Checkpoint
依靠 LSM-tree 本身的机制(Log-structured,Compaction)做增量快照,具体流程如下:
- Memtable 刷盘,生成 L0 层文件,可能触发 Compaction
- 将变化的 SST 文件上传
- 向 JobManager 写入 Meta 信息
存在一些问题:
- 刷盘可能触发 Compaction,导致可能需要上传大量文件
- Compaction 开销较大,可能导致 write stall 和 CPU 突刺
- 事务化 sink 端到端延迟较大:2PC sink 在 checkpoint 时进行 commit,checkpoint 决定了 sink commit 的速度。
4.4 Generic Log-Based Incremental Checkpointing 思想
利用数据库中 WAL 的思想。更新数据先写 WAL,同时写 RocksDB。只需上传 WAL 数据,恢复时依靠 WAL 恢复数据。(可以做的事情:远程合并 WAL 文件)
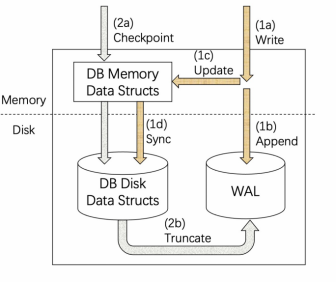
4.5 性能测试
- 优势: 端到端延迟,增量大小都是碾压的
- 劣势: 恢复时间比较长,可以理解,毕竟是重放。全量大小其实也不算大。
- 反压下的表现不大理想: 估计这个时候 CPU 差不多打满了,双写开销有点大。
4.6 美团对 Generic Log-Based Incremental Checkpointing 的优化
文件下载优化
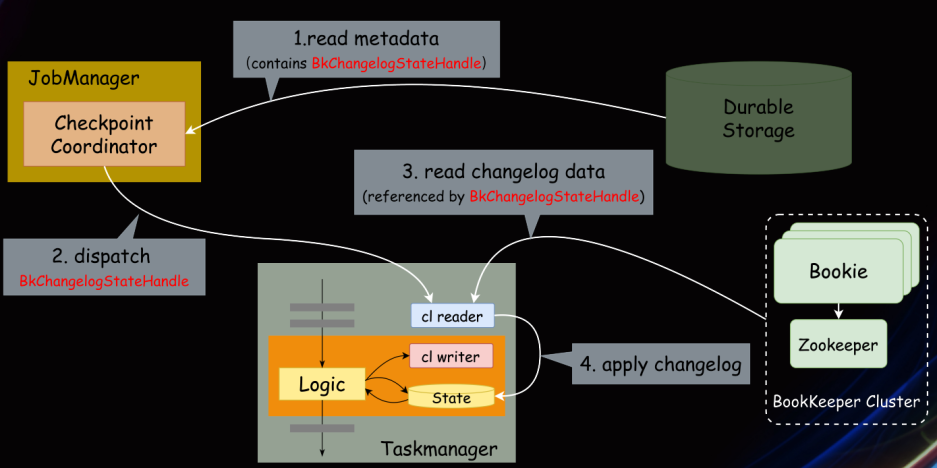
恢复时,每个 Task 会从 HDFS 下载 Changelog 恢复 Task,造成不必要的文件下载。实际上只需要下载一次即可:https://issues.apache.org/jira/browse/FLINK-27155
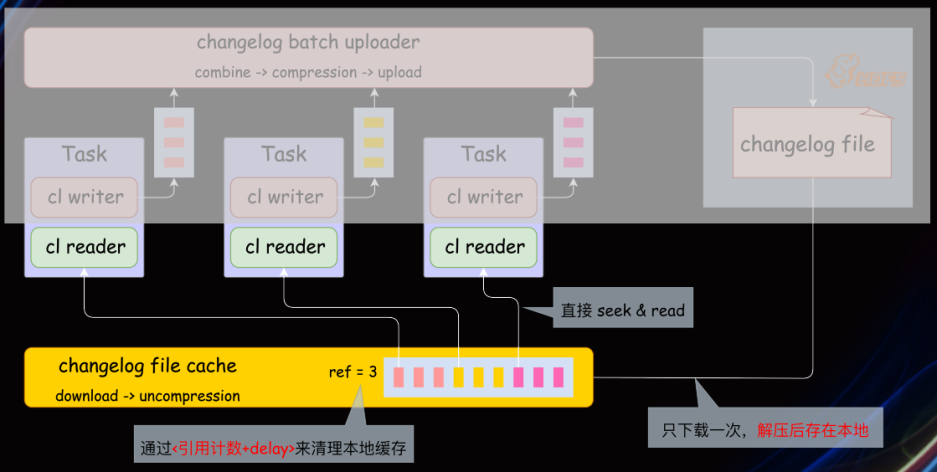
使用 Bookeeper 作为 Changelog 的存储
我觉得这一章说的真的很好,非常建议用心看。
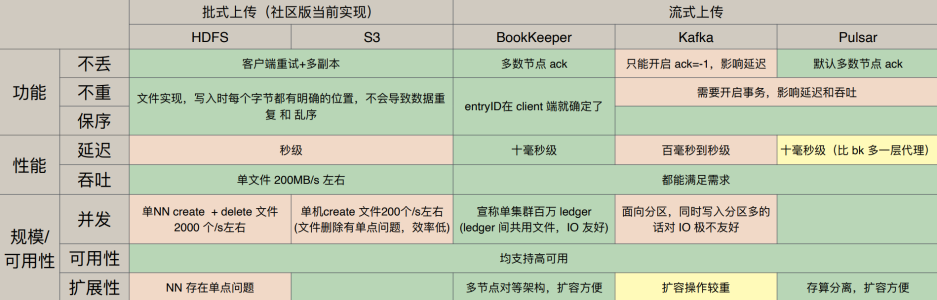
Changelog 对存储的需求

美团的选型
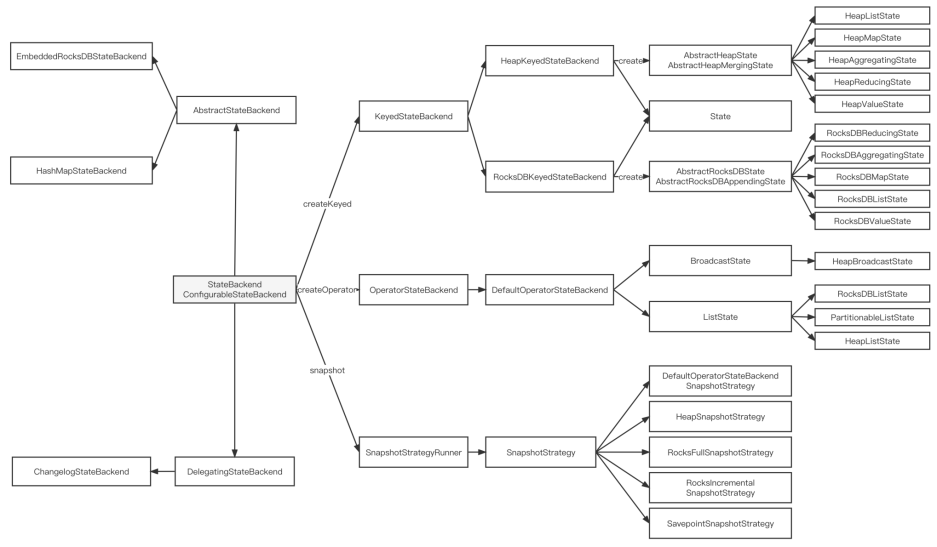
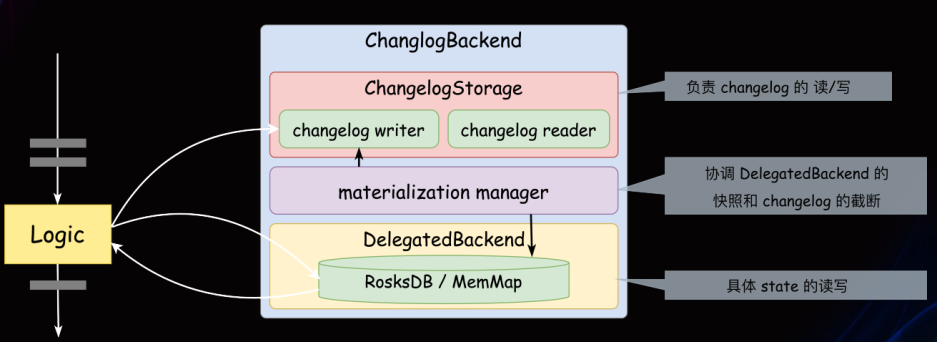
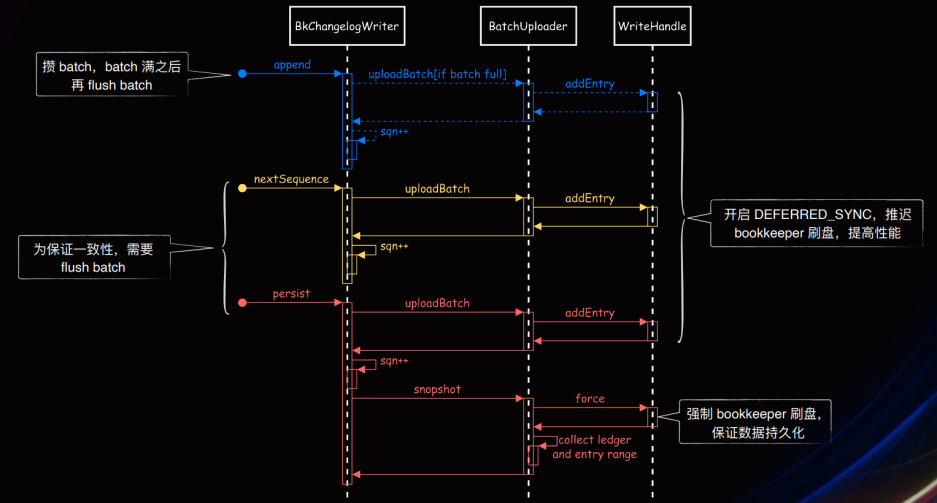
Changelog Backend 设计实现
Checkpoint 制作流程
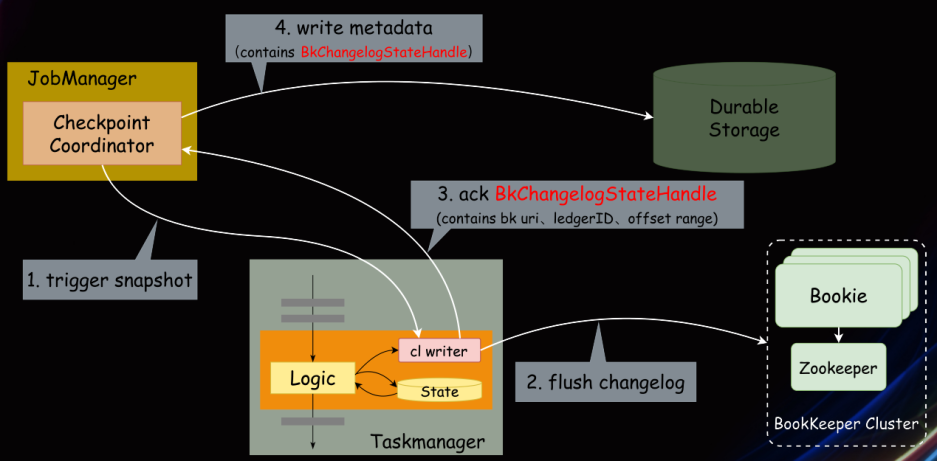
Changelog 写入 Bookeeper 流程
Checkpoint 恢复流程